
Yapay zekanın alanı, Büyük Dil Modelleri (LLM'ler) giderek sofistike bilişsel yetenekler sergileyerek hızla genişlemeye devam ediyor. Bunlar arasında, yaklaşık 14,8 milyar parametreye sahip FractalAIResearch/Fathom-R1-14B dikkate değer bir model olarak öne çıkıyor. Bu model, Fractal AI Research tarafından özellikle karmaşık matematiksel ve genel muhakeme görevlerinde mükemmel olmak üzere tasarlandı. Fathom-R1-14B'yi farklı kılan şey, bu yüksek performans seviyesine dikkate değer bir maliyet verimliliği ve pratik bir 16.384 (16K) token bağlam penceresi içinde ulaşabilmesidir. Bu makale, Fathom-R1-14B'nin geliştirilmesi, mimarisi, eğitim süreçleri, kıyaslanan performansı ve yerleşik yöntemlere dayalı pratik uygulamasına yönelik odaklanmış bir rehber sunarak teknik bir genel bakış sunmaktadır.
Fractal AI: Modelin Arkasındaki Yenilikçiler

Fathom-R1-14B, merkezi Mumbai, Hindistan'da bulunan, seçkin bir yapay zeka ve analiz firması olan Fractal'ın araştırma bölümü olan Fractal AI Research'ün bir ürünüdür. Fractal, Fortune 500 şirketlerine yapay zeka ve gelişmiş analiz çözümleri sunma konusunda küresel bir itibar kazanmıştır. Fathom-R1-14B'nin oluşturulması, Hindistan'ın yapay zeka sektöründeki büyüyen hedefleriyle yakından örtüşmektedir.
Hindistan'ın Yapay Zeka Hedefleri
Bu modelin geliştirilmesi, IndiaAI Misyonu bağlamında özellikle önemlidir. Fractal'ın Kurucu Ortağı, Grup İcra Kurulu Başkanı ve Başkan Yardımcısı Srikanth Velamakanni, Fathom-R1-14B'nin daha büyük bir girişimin erken bir göstergesi olduğunu belirtti. Şunları söyledi: "Hindistan'ın ilk büyük muhakeme modelini (LRM) IndiaAI misyonunun bir parçası olarak inşa etmeyi önerdik... Bu [Fathom-R1-14B] sadece nelerin mümkün olduğunun küçük bir kanıtı," çok daha büyük bir 70 milyar parametreli sürüm de dahil olmak üzere bir dizi model planlarına atıfta bulunarak. Bu stratejik yön, yapay zekada ulusal bir öz yeterlilik taahhüdünü ve yerli temel modellerin oluşturulmasını vurgulamaktadır. Fractal'ın yapay zekaya yaptığı daha geniş katkılar arasında, sağlık hizmetleri yardımı için çok modlu bir yapay zeka platformu olan Vaidya.ai gibi diğer etkili projeler de yer almaktadır. Bu nedenle, Fathom-R1-14B'nin açık kaynaklı bir araç olarak piyasaya sürülmesi, yalnızca küresel yapay zeka topluluğuna fayda sağlamakla kalmıyor, aynı zamanda Hindistan'ın gelişen yapay zeka ortamında önemli bir başarıyı da ifade ediyor.
Fathom-R1-14B'nin Temel Tasarımı ve Mimari Planı
Fathom-R1-14B'nin etkileyici yetenekleri, muhakeme görevleri için optimize edilmiş, özenle seçilmiş bir temel ve sağlam bir mimari tasarım üzerine kurulmuştur.
Fathom-R1-14B'nin yolculuğu, Deepseek-R1-Distilled-Qwen-14B'nin temel model olarak seçilmesiyle başladı. Bu modelin "damıtılmış" doğası, özellikle saygın Qwen ailesinden gelenler olmak üzere, orijinalin yeteneklerinin önemli bir bölümünü korumak üzere tasarlanmış, daha büyük bir ana modelin daha kompakt ve hesaplama açısından verimli bir türevi olduğunu gösterir. Bu, Fractal AI Research'ün daha sonra özel eğitim sonrası tekniklerle titizlikle geliştirdiği güçlü bir başlangıç noktası sağladı. Model, işlemleri için tipik olarak bfloat16 (Beyin Kayan Nokta Formatı) hassasiyetini kullanır; bu, hesaplama hızı ile karmaşık hesaplamalar için gereken sayısal doğruluk arasında etkili bir denge kurar.
Fathom-R1-14B, Transformer model ailesi içinde güçlü bir yineleme olan Qwen2 mimarisi üzerine kurulmuştur. Transformer modelleri, büyük ölçüde yenilikçi kendi kendine dikkat mekanizmaları sayesinde, yüksek performanslı LLM'ler için mevcut standarttır. Bu mekanizmalar, modelin çıktısını oluştururken, bir giriş dizisindeki farklı tokenlerin (kelimeler, alt kelimeler veya matematiksel semboller olsun) önemini dinamik olarak tartmasını sağlar. Bu yetenek, karmaşık matematiksel problemler ve nüanslı mantıksal argümanlarda mevcut olan karmaşık bağımlılıkları anlamak için çok önemlidir.
Modelin, yaklaşık 14,8 milyar parametre ile karakterize edilen ölçeği, performansında önemli bir faktördür. Esasen sinir ağının katmanları içindeki öğrenilmiş sayısal değerler olan bu parametreler, modelin bilgi ve muhakeme yeteneklerini kodlar. Bu boyuttaki bir model, eğitim verilerinden karmaşık kalıpları yakalamak ve temsil etmek için önemli bir kapasite sunar.
16K Bağlam Penceresinin Önemi
Kritik bir mimari özellik, 16.384 tokenlik bağlam penceresidir. Bu, tek bir işlemde işlenebilecek birleşik giriş isteminin ve model tarafından oluşturulan çıktının maksimum uzunluğunu belirler. Bazı modeller çok daha büyük bağlam pencerelerine sahipken, Fathom-R1-14B'nin 16K kapasitesi kasıtlı ve pragmatik bir tasarım seçimidir. Ayrıntılı problem ifadelerini, kapsamlı adım adım muhakeme zincirlerini (Olimpiyat seviyesindeki matematikte sıklıkla gerektiği gibi) ve kapsamlı cevapları barındıracak kadar büyüktür. Önemli olarak, bu, son derece uzun dizilerdeki dikkat mekanizmalarıyla ilişkilendirilebilen ve Fathom-R1-14B'yi çıkarım sırasında daha çevik ve daha az kaynak yoğun hale getiren hesaplama maliyetinin kuadratik ölçeklenmesine neden olmadan başarılır.
Fathom-R1-14B Gerçekten, Gerçekten Uygun Maliyetli
Fathom-R1-14B'nin en çarpıcı yönlerinden biri, eğitim sonrası sürecinin verimliliğidir. Modelin birincil sürümü, yaklaşık 499 ABD Doları maliyetle ince ayarlandı. Bu dikkate değer ekonomik uygulanabilirlik, aşırı hesaplama harcaması yapmadan muhakeme becerilerini en üst düzeye çıkarmaya odaklanan sofistike, çok yönlü bir eğitim stratejisiyle elde edildi.
Bu verimli uzmanlaşmanın temelini oluşturan temel teknikler şunları içeriyordu:
- Denetimli İnce Ayar (SFT): Bu temel aşama, temel modelin, özellikle gelişmiş matematiksel muhakemeye uyarlanmış, yüksek kaliteli, küratörlü bir problem-çözüm çiftleri veri kümesi üzerinde eğitilmesini içeriyordu. SFT aracılığıyla model, doğru problem çözme yollarını ve mantıksal çıkarımı taklit etmeyi öğrendi.
- Yinelemeli Müfredat Öğrenimi: Modeli bir kerede tüm problem zorluğu yelpazesine maruz bırakmak yerine, bu strateji zorlukları kademeli bir şekilde sunar. Model, daha basit matematiksel problemlerle başlar ve AIME ve HMMT'den gelenler gibi daha karmaşık olanlara ilerler. Bu yapılandırılmış yaklaşım, modelin son derece zorlu görevlerin üstesinden gelmeden önce güçlü bir temel oluşturmasına izin vererek daha istikrarlı ve etkili öğrenmeyi kolaylaştırır. Bu teknik, temel bir öncül model olan
Fathom-R1-14B-V0.6'nın geliştirilmesinde merkezi bir rol oynamıştır. - Model Birleştirme: Son Fathom-R1-14B modeli, özellikle ince ayarlanmış iki öncül modelin birleşimidir:
Fathom-R1-14B-V0.6(Yinelemeli Müfredat SFT'den geçen) veFathom-R1-14B-V0.4("En Kısa Zincirler" ile SFT'ye odaklanan, muhtemelen çözümlerde özlülüğü vurgulayan). Biraz farklı odaklarla eğitilmiş modelleri birleştirerek, ortaya çıkan model daha geniş bir güç yelpazesini miras alır.
Bu titiz eğitim sürecinin genel amacı, "öz ama doğru matematiksel muhakeme" aşılamaktı.
Fractal AI Research ayrıca, Fathom-R1-14B-RS adlı bir varyantla alternatif bir eğitim yolu da keşfetti. Bu sürüm, SFT'nin yanı sıra GRPO (Genelleştirilmiş Ödül İtme Optimizasyonu) olarak adlandırılan bir algoritma kullanarak Takviyeli Öğrenme (RL)'yi içeriyordu. Bu yaklaşım karşılaştırılabilir yüksek performans sağlarken, eğitim sonrası maliyeti 967 ABD Doları ile biraz daha yüksekti. Her iki sürümün geliştirilmesi, muhakeme performansını verimli bir şekilde optimize etmek için çeşitli metodolojileri keşfetme taahhüdünün altını çizmektedir. Şeffaflık taahhüdünün bir parçası olarak, Fractal AI Research eğitim tariflerini ve veri kümelerini açık kaynaklı hale getirmiştir.
Performans Kıyaslamaları: Muhakeme Mükemmelliğini Ölçmek
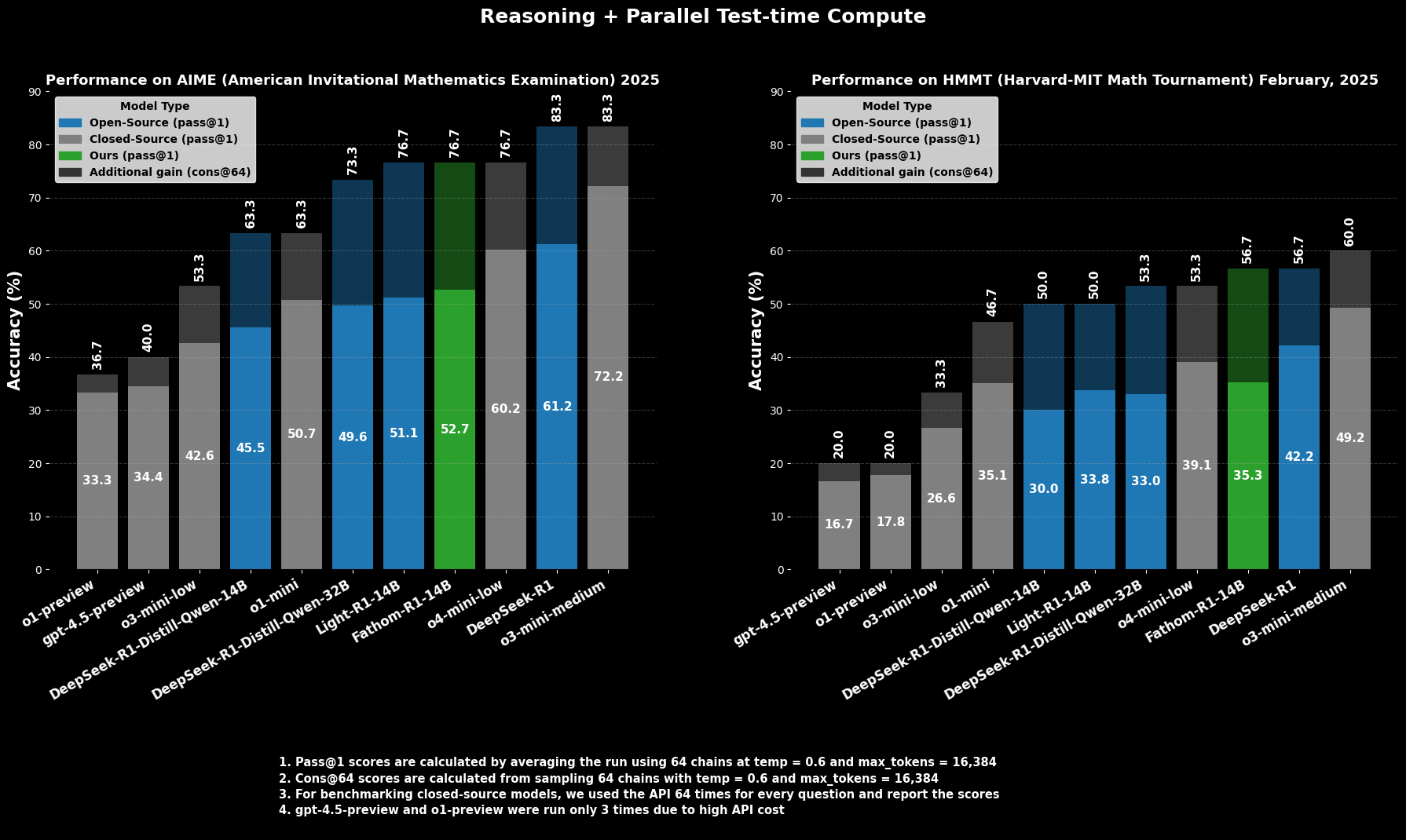
Fathom-R1-14B'nin yeterliliği sadece teorik değildir; uluslararası alanda tanınan titiz matematiksel muhakeme kıyaslamalarında etkileyici performansla kanıtlanmıştır.
AIME ve HMMT'de Başarı
Zorlu bir üniversite öncesi matematik yarışması olan AIME2025 (American Invitational Mathematics Examination)'te Fathom-R1-14B, %52,71 Pass@1 doğruluğu elde ediyor. Pass@1 metriği, modelin tek bir denemede doğru bir çözüm ürettiği problemlerin yüzdesini gösterir. Test zamanında daha fazla hesaplama bütçesine izin verildiğinde, cons@64 (64 örneklenmiş çözüm arasındaki tutarlılık) kullanılarak değerlendirildiğinde, AIME2025'teki doğruluğu etkileyici bir şekilde %76,7'ye yükseliyor.
Benzer şekilde, bir başka üst düzey yarışma olan HMMT25 (Harvard-MIT Mathematics Tournament)'te model, %35,26 Pass@1 puanı alıyor ve bu da %56,7 cons@64'e yükseliyor. Bu puanlar, modelin 16K token çıktı bütçesi dahilinde elde edildiği ve pratik dağıtım hususlarını yansıttığı için özellikle dikkate değerdir.
Karşılaştırmalı Performans
Karşılaştırmalı değerlendirmelerde, Fathom-R1-14B, bu özel matematiksel kıyaslamalarda Pass@1'de benzer veya hatta daha büyük boyutlardaki diğer açık kaynaklı modellerden önemli ölçüde daha iyi performans gösteriyor. Daha çarpıcı bir şekilde, özellikle cons@64 metriği dikkate alındığında performansı, genellikle çok daha büyük kaynaklara eriştiği varsayılan bazı yetenekli kapalı kaynaklı modellerle rekabetçi bir konuma getiriyor. Bu, Fathom-R1-14B'nin parametrelerini ve eğitimini yüksek doğrulukta muhakemeye çevirmedeki verimliliğini vurgulamaktadır.
Fathom-R1-14B'yi Çalıştırmayı Deneyelim
https://nodeshift.com/blog/how-to-install-fathom-r1-14b-the-most-efficient-sota-math-reasoning-llm
Bu bölüm, bir Python ortamında Hugging Face transformers kitaplığını kullanarak Fathom-R1-14B'yi çalıştırmaya yönelik odaklanmış bir rehber sunmaktadır. Bu yaklaşım, yerel olarak veya bulut sağlayıcıları aracılığıyla yetenekli GPU donanımına erişimi olan kullanıcılar için çok uygundur. Burada özetlenen adımlar, bu tür modelleri dağıtmak için yerleşik uygulamaları yakından takip etmektedir.
Ortam Yapılandırması
Uygun bir Python ortamı kurmak çok önemlidir. Aşağıdaki adımlar, Linux tabanlı bir sistemde (veya Linux için Windows Alt Sistemi) Conda kullanarak yaygın bir kurulumu ayrıntılı olarak açıklamaktadır:
Makinenize Erişim: Uzak bir bulut GPU örneği kullanıyorsanız, SSH aracılığıyla bağlanın.Bash
# Örnek: ssh your_user@your_gpu_instance_ip -p YOUR_PORT -i /path/to/your/ssh_key
GPU Tanımasını Doğrulayın: Sistemde NVIDIA GPU'nun tanındığından ve sürücülerin doğru şekilde yüklendiğinden emin olun.Bash
nvidia-smi
Bir Conda Ortamı Oluşturun ve Etkinleştirin: Proje bağımlılıklarını izole etmek iyi bir uygulamadır.Bash
conda create -n fathom python=3.11 -y
conda activate fathom
Gerekli Kütüphaneleri Yükleyin: PyTorch'u (CUDA sürümünüzle uyumlu), Hugging Face transformers, accelerate (verimli model yükleme ve dağıtım için), notebook (Jupyter için) ve ipywidgets (not defteri etkileşimi için) yükleyin.Bash
# GPU'nuzun CUDA araç takımıyla uyumlu bir PyTorch sürümü yüklediğinizden emin olun
# CUDA 11.8 için örnek:
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Veya CUDA 12.1 için:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
conda install -c conda-forge --override-channels notebook -y
pip install ipywidgets transformers accelerate
Jupyter Not Defterinde Python Tabanlı Çıkarım
Ortam hazırlandıktan sonra, Fathom-R1-14B'yi yüklemek ve etkileşimde bulunmak için bir Jupyter Not Defteri kullanabilirsiniz.
Jupyter Not Defteri Sunucusunu Başlatın: Uzak bir sunucuda, uzaktan erişime izin veren Jupyter Not Defteri'ni başlatın ve bir bağlantı noktası belirtin.Bash
jupyter notebook --no-browser --port=8888 --allow-root
Uzaktan çalışıyorsanız, Jupyter arayüzüne erişmek için büyük olasılıkla yerel makinenizden SSH bağlantı noktası yönlendirmesi ayarlamanız gerekir:Bash
# Örnek: ssh -N -L localhost:8889:localhost:8888 your_user@your_gpu_instance_ip
Ardından, web tarayıcınızda http://localhost:8889 (veya seçtiğiniz yerel bağlantı noktası) açın.
Model Etkileşimi için Python Kodu: Yeni bir Jupyter Not Defteri oluşturun ve aşağıdaki Python kodunu kullanın:Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Hugging Face'den model kimliğini tanımlayın
model_id = "FractalAIResearch/Fathom-R1-14B"
print(f"Loading tokenizer for {model_id}...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print(f"Loading model {model_id} (this may take a while)...")
# Verimlilik için bfloat16 hassasiyeti ve otomatik dağıtım için device_map ile modeli yükleyin
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # GPU'nuz destekliyorsa bfloat16 kullanın
device_map="auto", # Model katmanlarını mevcut donanım arasında otomatik olarak dağıtır
trust_remote_code=True # Bazı modeller bunu gerektirebilir
)
print("Model ve tokenizer başarıyla yüklendi.")
# Örnek bir matematiksel istem tanımlayın
prompt = """Question: Natalia, Nisan ayında 48 arkadaşına klips sattı ve Mayıs ayında yarısı kadar klips sattı. Haziran ayında, Mayıs ayından 4 klips daha fazla sattı. Natalia, Nisan, Mayıs ve Haziran aylarında toplam kaç klips sattı? Adım adım bir çözüm sağlayın.
Solution:"""
print(f"\nPrompt:\n{prompt}")
# Giriş istemini tokenleştirin
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Girişlerin modelin cihazında olduğundan emin olun
print("\nGenerating solution...")
# Modelden çıktıyı oluşturun
# Farklı türdeki problemler için oluşturma parametrelerini ayarlayın
outputs = model.generate(
**inputs,
max_new_tokens=768, # Çözüm için oluşturulacak maksimum yeni token sayısı
num_return_sequences=1, # Oluşturulacak bağımsız dizilerin sayısı
temperature=0.1, # Daha deterministik, olgusal çıktılar için daha düşük sıcaklık
top_p=0.7, # top_p ile çekirdek örnekleme kullanın
do_sample=True # Etki için sıcaklık ve top_p için örneklemeyi etkinleştirin
)
# Oluşturulan tokenleri bir dizeye kod çözün
solution_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\nGenerated Solution:\n")
print(solution_text)
Sonuç: Fathom-R1-14B'nin Erişilebilir Yapay Zeka Üzerindeki Etkisi
FractalAIResearch/Fathom-R1-14B, çağdaş yapay zeka arenasında teknik dehanın zorlayıcı bir göstergesi olarak duruyor. Yaklaşık 14,8 milyar parametreye, Qwen2 mimarisine ve 16K token bağlam penceresine sahip özel tasarımı, çığır açan ve uygun maliyetli eğitimle (birincil sürüm için yaklaşık 499 ABD Doları) birleştiğinde, öncü performans sunan bir LLM ile sonuçlandı. Bu, AIME ve HMMT gibi yorucu matematiksel muhakeme kıyaslamalarındaki puanlarıyla kanıtlanmaktadır.
Fathom-R1-14B, yapay zeka muhakemesinin sınırlarının akıllı tasarım ve verimli metodolojilerle geliştirilebileceğini, yüksek performanslı yapay zekanın daha demokratik ve yaygın olarak faydalı olduğu bir geleceği teşvik ettiğini ikna edici bir şekilde göstermektedir.
Geliştirici Ekibinizin maksimum verimlilikle birlikte çalışması için entegre, Hepsi Bir Arada bir platform mu istiyorsunuz?
Apidog tüm taleplerinizi karşılıyor ve Postman'in yerini çok daha uygun bir fiyata alıyor!


